
YARNスケジューラは、Fifo、Capacity、Fairスケジューラなど、さまざまな実装が存在する興味深い領域です。 また、さまざまなシナリオやワークロードに合わせてスケジューラのパフォーマンスを向上させるために、いくつかの最適化も行われています。 各スケジューリングアルゴリズムには独自の特徴があり、公平性、容量保証、リソース可用性など、多くの要素によってスケジューリングの決定が左右されます。 本番クラスタにデプロイする前に、スケジューリングアルゴリズムを十分に評価することが非常に重要です。 残念ながら、現在、スケジューリングアルゴリズムを評価するのは簡単ではありません。 実際のクラスタで評価するには、常に時間とコストがかかり、十分な規模のクラスタを見つけることも非常に困難です。 したがって、特定のワークロードに対するスケジューリングアルゴリズムの性能を予測できるシミュレータは非常に役立ちます。
YARNスケジューラ負荷シミュレータ (SLS) は、まさにそのようなツールであり、単一のマシンで大規模なYARNクラスタとアプリケーション負荷をシミュレートできます。このシミュレータは、研究者や開発者が新しいスケジューラ機能のプロトタイプを作成し、その動作とパフォーマンスをある程度の確信を持って予測するためのツールを提供することにより、YARNのさらなる発展に非常に役立ちます。そのため、迅速なイノベーションを促進します。 o シミュレータは、実際のYARN ResourceManager を使用し、同じJVM内からNM/AMs ハートビートイベントを処理およびディスパッチすることで、NodeManager および ApplicationMaster をシミュレートすることにより、ネットワークファクターを取り除きます。 スケジューラの動作とパフォーマンスを追跡するために、スケジューララッパーが実際のスケジューラをラップします。
クラスタのサイズとアプリケーションの負荷は、Apache Rumen を採用してジョブ履歴ファイルから直接生成される構成ファイルからロードできます。
シミュレータは、実行中にリアルタイムメトリックを生成します。これには以下が含まれます。
クラスタ全体と各キューのリソース使用量。これらは、クラスタとキューの容量を構成するために利用できます。
詳細なアプリケーション実行トレース (シミュレートされた時間と関連付けて記録されます)。これは、スケジューラの動作 (個々のジョブのターンアラウンドタイム、スループット、公平性、容量保証など) を理解/検証するために分析できます。
各スケジューラ操作 (割り当て、処理など) の時間コストなど、スケジューリングアルゴリズムのいくつかの主要なメトリクス。これらは、Hadoop開発者がコードスポットとスケーラビリティの限界を見つけるために利用できます。
実際のジョブトレースを使用して、実際のクラスタなしで大規模にスケジューラを実行します。
実際のワークロードをシミュレートできる。
次の図は、シミュレータの実装アーキテクチャを示しています。
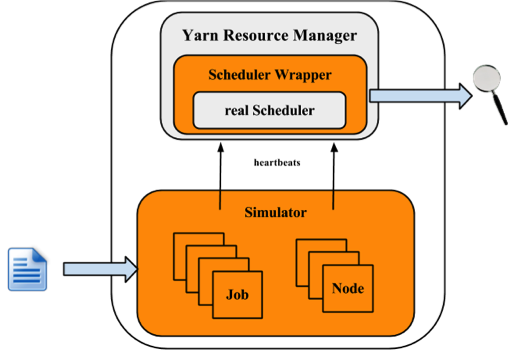
シミュレータは、ワークロードトレース、または合成負荷分布を入力として受け取り、クラスタとアプリケーションの情報を生成します。 各NMおよびAMについて、シミュレータはそれらの実行をシミュレートするシミュレータを構築します。 すべてのNM/AMシミュレータはスレッドプールで実行されます。 シミュレータはYARNリソースマネージャーを再利用し、スケジューラからラッパーを構築します。 スケジューララッパーはスケジューラの動作を追跡し、いくつかのログを生成します。これらはシミュレータの出力であり、さらに分析できます。
エンジニアリング
QA
ソリューション/販売。
このセクションでは、シミュレータの使用方法を示します。 ここで、$HADOOP_ROOT はHadoopのインストールディレクトリを表すとします。 Hadoopを自分でビルドする場合、$HADOOP_ROOT は hadoop-dist/target/hadoop-$VERSION です。 シミュレータは $HADOOP_ROOT/share/hadoop/tools/sls にあります。 フォルダ sls には、bin、html、sample-conf、sample-data の4つのディレクトリが含まれています。
bin: シミュレータの実行スクリプトが含まれています。
html: ユーザーは、これらのリアルタイムトラッキングチャートをオフラインモードで再現することもできます。 realtimetrack.json を $HADOOP_ROOT/share/hadoop/tools/sls/html/showSimulationTrace.html にアップロードするだけです。 ブラウザのセキュリティの問題のため、ファイル realtimetrack.json と showSimulationTrace.html を同じディレクトリに配置する必要があります。
sample-conf: シミュレータの構成を指定します。
sample-data: シミュレータの入力の生成に使用できるrumenトレースの例を提供します。
以下のセクションでは、シミュレータの使用方法をステップバイステップで説明します。 開始する前に、コマンド hadoop が$PATH 環境パラメータに含まれていることを確認してください。
開始する前に、Hadoopとシミュレータが正しく構成されていることを確認してください。 Hadoopとシミュレータのすべての構成ファイルは、ResourceManager とYARNスケジューラが構成を読み込むディレクトリ $HADOOP_ROOT/etc/hadoop に配置する必要があります。 ディレクトリ $HADOOP_ROOT/share/hadoop/tools/sls/sample-conf/ には、デモを開始するために使用できるいくつかの構成例が用意されています。
HadoopとYARNスケジューラの構成については、YarnのWebサイト (https://hadoop.dokyumento.jp/docs/current/hadoop-yarn/hadoop-yarn-site/) を参照してください。
シミュレータの場合、ファイル $HADOOP_ROOT/etc/hadoop/sls-runner.xml から構成情報を読み込みます。
ここでは、sls-runner.xml の各構成パラメータについて説明します。 $HADOOP_ROOT/share/hadoop/tools/sls/sample-conf/sls-runner.xml には、これらの構成パラメータのすべてのデフォルト値が含まれていることに注意してください。
yarn.sls.runner.pool.size
シミュレータはスレッドプールを使用してNM とAM の実行をシミュレートし、このパラメータはプール内のスレッド数を指定します。
yarn.sls.nm.memory.mb
各NMSimulator の合計メモリ。
yarn.sls.nm.vcores
各NMSimulator の合計vCore数。
yarn.sls.nm.heartbeat.interval.ms
各NMSimulator のハートビート間隔。
yarn.sls.am.heartbeat.interval.ms
各AMSimulator のハートビート間隔。
yarn.sls.am.type.mapreduce
MapReduceのようなアプリケーションのAMSimulator 実装。 ユーザーは、他のタイプのアプリケーションの実装を指定できます。
yarn.sls.container.memory.mb
各コンテナシミュレータに必要なメモリ。
yarn.sls.container.vcores
各コンテナシミュレータに必要なvCore数。
yarn.sls.runner.metrics.switch
シミュレータは、Metrics を導入して、重要なコンポーネントと操作の動作を測定します。 このフィールドは、メトリクスの実行を開く (ON) か閉じる (OFF) かを指定します。
yarn.sls.metrics.web.address.port
シミュレータがリアルタイムトラッキングを提供するために使用するポート。 デフォルト値は10001です。
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fifo.FifoScheduler
Fifoスケジューラのスケジューラメトリクスの実装。
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
Fairスケジューラのスケジューラメトリクスの実装。
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
Capacityスケジューラのスケジューラメトリクスの実装。
シミュレータは、rumenトレースと独自の入力トレースの2種類の入力ファイルをサポートしています。 シミュレータを起動するスクリプトは slsrun.sh です。
$ cd $HADOOP_ROOT/share/hadoop/tools/sls
$ bin/slsrun.sh
Usage: slsrun.sh <OPTIONS>
--tracetype=<SYNTH | SLS | RUMEN>
--tracelocation=<FILE1,FILE2,...>
(deprecated --input-rumen=<FILE1,FILE2,...> | --input-sls=<FILE1,FILE2,...>)
--output-dir=<SLS_SIMULATION_OUTPUT_DIRECTORY>
[--nodes=<SLS_NODES_FILE>]
[--track-jobs=<JOBID1,JOBID2,...>]
[--print-simulation]
--input-rumen: 入力rumenトレースファイル。 ユーザーは複数のファイルをコンマで区切って入力できます。 1つのトレース例は、$HADOOP_ROOT/share/hadoop/tools/sls/sample-data/2jobs2min-rumen-jh.json にあります。 これは、--tracetype=RUMEN --tracelocation=<path_to_trace> と同等です。
--input-sls: シミュレータ独自のファイル形式。 シミュレータは、rumenトレースをslsトレースに変換するツール (rumen2sls.sh) も提供しています。 sls入力jsonファイルの例については、付録を参照してください。 これは、--tracetype=SLS --tracelocation=<path_to_trace> と同等です。
--tracetype: これはトレース生成を設定するための新しい方法で、RUMEN、SLS、またはSYNTHの値を取り、3種類の負荷生成をトリガーします。
--tracelocation: 上記のトレースタイプに一致する入力ファイルへのパス。
--output-dir: 生成された実行ログとメトリックの出力ディレクトリ。
--nodes: クラスタトポロジ。デフォルトでは、シミュレーターは入力JSONファイルから取得したトポロジを使用します。ユーザーはこのパラメーターを設定することで新しいトポロジを指定できます。トポロジファイルの形式については、付録を参照してください。
--track-jobs: シミュレーターの実行中に追跡される特定のジョブ。カンマで区切ります。
--print-simulation: シミュレーターの実行前に、ノード数、アプリケーション、タスク、および各アプリケーションの情報を含むシミュレーション情報を表示するかどうか。
rumen形式と比較して、sls形式ははるかに単純であり、ユーザーはさまざまなワークロードを簡単に生成できます。シミュレーターは、rumenトレースをslsトレースに変換するツールも提供しています。
$ bin/rumen2sls.sh
--rumen-file=<RUMEN_FILE>
--output-dir=<SLS_OUTPUT_DIRECTORY>
[--output-prefix=<SLS_FILE_PREFIX>]
--rumen-file: rumen形式のファイル。サンプルトレースは、ディレクトリsample-dataに提供されています。
--output-dir: 生成されたシミュレーショントレースの出力ディレクトリ。この出力ディレクトリには、すべてのジョブとタスク情報を含む1つのトレースファイルと、トポロジ情報を示す別のファイルの2つのファイルが生成されます。
--output-prefix: 生成されるファイルのプレフィックス。デフォルト値は「sls」で、生成される2つのファイルはsls-jobs.jsonとsls-nodes.jsonです。
YARNスケジューラー負荷シミュレーターは、Metricsを統合して、実行中のアプリケーションとコンテナ、クラスタで使用可能なリソース、スケジューラーの操作時間など、重要なコンポーネントと操作の動作を測定します。スイッチyarn.sls.runner.metrics.switchがONに設定されている場合、Metricsは実行され、ユーザーが指定した--output-dirディレクトリにログを出力します。ユーザーはシミュレーターの実行中にこれらの情報を追跡でき、実行後にこれらのログを分析してスケジューラーのパフォーマンスを評価することもできます。
シミュレーターは、実行中の状態をリアルタイムで追跡するためのインターフェースを提供します。ユーザーは、http://host:port/simulateにアクセスして実行全体を追跡し、http://host:port/trackにアクセスして特定のジョブまたはキューを追跡できます。ここで、hostはシミュレーターを実行する場所、portはyarn.sls.metrics.web.address.portで設定された値(デフォルト値は10001)です。
ここでは、Webページに表示される各チャートについて説明します。
最初の図は、実行中のアプリケーションとコンテナの数を示しています。
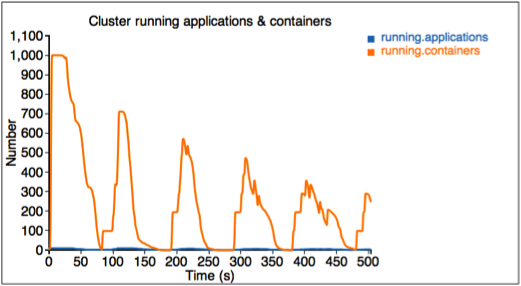
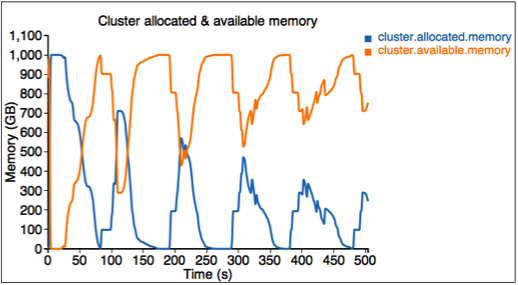
2番目の図は、クラスタ内の割り当て済みリソースと使用可能リソース(メモリ)を示しています。
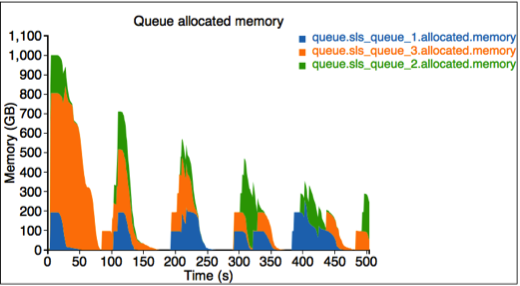
3番目の図は、各キューに割り当てられたリソースを示しています。ここでは、sls_queue_1、sls_queue_2、sls_queue_3の3つのキューがあります。最初の2つのキューは25%のシェアで構成され、最後のキューは50%のシェアを持っています。
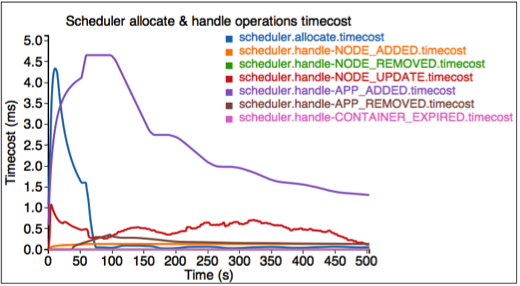
4番目の図は、各スケジューラー操作の時間コストを示しています。
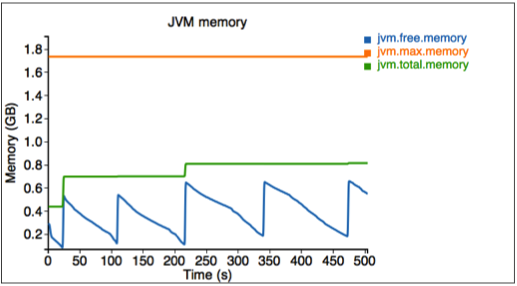
最後に、シミュレーターで使用されるメモリを測定します。
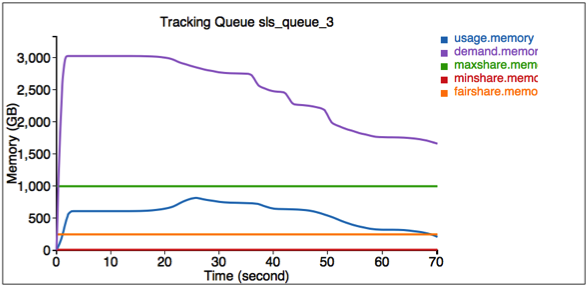
シミュレーターは、特定のジョブとキューを追跡するためのインターフェースも提供します。これらの情報を取得するには、http://<Host>:<Port>/trackにアクセスしてください。
最初の図は、キューSLS_Queue_1のリソース使用状況を示しています。
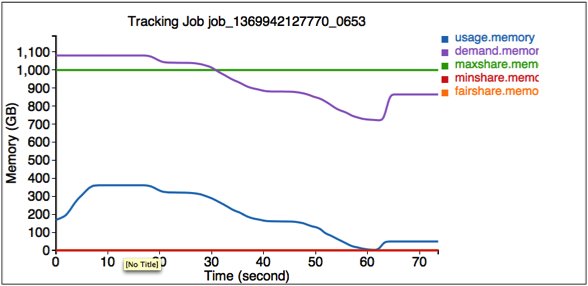
2番目の図は、ジョブjob_1369942127770_0653のリソース使用状況を示しています。
シミュレーターが終了すると、すべてのログは$HADOOP_ROOT/share/hadoop/tools/sls/bin/slsrun.shの--output-dirで指定された出力ディレクトリに保存されます。
ファイルrealtimetrack.json: 1秒ごとにすべてのリアルタイム追跡ログを記録します。
ファイルjobruntime.csv: シミュレーター内のすべてのジョブの開始時刻と終了時刻を記録します。
フォルダーmetrics: Metricsによって生成されたログ。
ユーザーは、オフラインモードでこれらのリアルタイム追跡チャートを再現することもできます。 realtimetrack.jsonを$HADOOP_ROOT/share/hadoop/tools/sls/html/showSimulationTrace.htmlにアップロードするだけです。ブラウザのセキュリティの問題のため、ファイルrealtimetrack.jsonとshowSimulationTrace.htmlを同じディレクトリに配置する必要があります。
合成負荷ジェネレーターは、負荷の分布駆動型生成を提供することにより、SLSネイティブおよびRUMENトレースの広範な性質を補完します。負荷ジェネレーターは、JobStoryProducer(rumenと互換性があり、そのため後の統合のためにgridmixと互換性があります)として編成されています。乱数ジェネレーターをシードすることで、結果はランダム化されますが決定論的であるため、再現可能です。生成されるジョブは、/workloads/job_class階層を中心に編成されます。これにより、同様の動作を持つジョブを簡単にグループ化して分類できます(たとえば、長時間実行されるコンテナを持つジョブ、またはmaponly計算など)。ユーザーは、マッパー/レデューサーの数、マッパー/レデューサーの期間、コンテナのサイズ(メモリ/ CPU)、予約の可能性など、多くの重要なパラメーターの平均と標準偏差を制御できます。少数のオプションから選択する場合は重み付きランダムサンプリングを使用し、幅広い値の範囲から選択する場合は対数正規分布(負の値を避けるため)を使用します。対数正規分布に関する付録を参照してください。
SLSのSYNTHモードは、広範な入力ファイルを必要とせずに非常に大きな負荷を生成するのに非常に便利です。これにより、効率的かつコンパクトな方法で、幅広いユースケースを簡単に探索できます(たとえば、100kジョブのシミュレーションを想像し、異なる実行でマッパーの平均数またはタスクの平均期間を調整するだけです)。
このセクションでは、SLSでリソースタイプを使用する方法について説明します。
これは、実際のクラスタのリソースタイプを構成する方法と同じです。次の例のように、yarn-site.xmlでアイテムyarn.resource-typesを設定します。
<property> <name>yarn.resource-types</name> <value>resource-type1, resource-type2</value> </property>
次の例のように、関連するアイテムをsls-runner.xmlに追加することにより、各ノードのリソースサイズを指定します。値はSLSのすべてのノードに適用されます。メモリとvcores以外のリソースのデフォルト値は0です。
<property> <name>yarn.sls.nm.resource-type1</name> <value>10</value> </property> <property> <name>yarn.sls.nm.resource-type2</name> <value>10</value> </property>
リソースタイプはSLS JSON入力形式でサポートされていますが、他の2つの形式(SYNTHとRUMEN)ではサポートされていません。SLS JSON入力形式で機能させるには、タスクコンテナとAMコンテナの両方でリソースサイズを指定できます。次に例を示します。
{
"job.start.ms" : 0,
"am.memory-mb": 2048,
"am.vcores": 2,
"am.resource-type1": 2,
"am.resource-type2": 2,
"job.tasks" : [ {
"container.duration.ms": 5000
"container.memory-mb": 1024,
"container.vcores": 1,
"container.resource-type1": 1,
"container.resource-type2": 1
}
}
YARN-1021は、Hadoop YARNプロジェクトにYARNスケジューラー負荷シミュレーターを導入するメインのJIRAです。 YARN-6363は、SLSに合成負荷ジェネレーターを導入するメインのJIRAです。
ここでは、2つのジョブを含むsls jsonファイルの例を示します。最初のジョブには3つのマップタスクがあり、2番目のジョブには2つのマップタスクがあります。
{
"num.nodes": 3, // total number of nodes in the cluster
"num.racks": 1 // total number of racks in the cluster, it divides num.nodes into the racks evenly, optional, the default value is 1
}
{
"am.type" : "mapreduce", // type of AM, optional, the default value is "mapreduce"
"job.start.ms" : 0, // job start time
"job.end.ms" : 95375, // job finish time, optional, the default value is 0
"job.queue.name" : "sls_queue_1", // the queue job will be submitted to
"job.id" : "job_1", // the job id used to track the job, optional. The default value, an zero-based integer increasing with number of jobs, is used if this is not specified or job.count > 1
"job.user" : "default", // user, optional, the default value is "default"
"job.count" : 1, // number of jobs, optional, the default value is 1
"job.tasks" : [ {
"count": 1, // number of tasks, optional, the default value is 1
"container.host" : "/default-rack/node1", // host the container asks for
"container.start.ms" : 6664, // container start time, optional
"container.end.ms" : 23707, // container finish time, optional
"container.duration.ms": 50000, // duration of the container, optional if start and end time is specified
"container.priority" : 20, // priority of the container, optional, the default value is 20
"container.type" : "map" // type of the container, could be "map" or "reduce", optional, the default value is "map"
}, {
"container.host" : "/default-rack/node3",
"container.start.ms" : 6665,
"container.end.ms" : 21593,
"container.priority" : 20,
"container.type" : "map"
}, {
"container.host" : "/default-rack/node2",
"container.start.ms" : 68770,
"container.end.ms" : 86613,
"container.priority" : 20,
"container.type" : "map"
} ]
}
{
"am.type" : "mapreduce",
"job.start.ms" : 105204,
"job.end.ms" : 197256,
"job.queue.name" : "sls_queue_2",
"job.id" : "job_2",
"job.user" : "default",
"job.tasks" : [ {
"container.host" : "/default-rack/node1",
"container.start.ms" : 111822,
"container.end.ms" : 133985,
"container.priority" : 20,
"container.type" : "map"
}, {
"container.host" : "/default-rack/node2",
"container.start.ms" : 111788,
"container.end.ms" : 131377,
"container.priority" : 20,
"container.type" : "map"
} ]
}
ここでは、合成ジェネレーターjsonファイルの例を示します。 (json非準拠の)インラインコメントを使用して、各パラメーターの使用方法を説明します。
{
"description" : "tiny jobs workload", //description of the meaning of this collection of workloads
"num_nodes" : 10, //total nodes in the simulated cluster
"nodes_per_rack" : 4, //number of nodes in each simulated rack
"num_jobs" : 10, // total number of jobs being simulated
"rand_seed" : 2, //the random seed used for deterministic randomized runs
// a list of “workloads”, each of which has job classes, and temporal properties
"workloads" : [
{
"workload_name" : "tiny-test", // name of the workload
"workload_weight": 0.5, // used for weighted random selection of which workload to sample from
"queue_name" : "sls_queue_1", //queue the job will be submitted to
//different classes of jobs for this workload
"job_classes" : [
{
"class_name" : "class_1", //name of the class
"class_weight" : 1.0, //used for weighted random selection of class within workload
//nextr group controls average and standard deviation of a LogNormal distribution that
//determines the number of mappers and reducers for thejob.
"mtasks_avg" : 5,
"mtasks_stddev" : 1,
"rtasks_avg" : 5,
"rtasks_stddev" : 1,
//averge and stdev input param of LogNormal distribution controlling job duration
"dur_avg" : 60,
"dur_stddev" : 5,
//averge and stdev input param of LogNormal distribution controlling mappers and reducers durations
"mtime_avg" : 10,
"mtime_stddev" : 2,
"rtime_avg" : 20,
"rtime_stddev" : 4,
//averge and stdev input param of LogNormal distribution controlling memory and cores for map and reduce
"map_max_memory_avg" : 1024,
"map_max_memory_stddev" : 0.001,
"reduce_max_memory_avg" : 2048,
"reduce_max_memory_stddev" : 0.001,
"map_max_vcores_avg" : 1,
"map_max_vcores_stddev" : 0.001,
"reduce_max_vcores_avg" : 2,
"reduce_max_vcores_stddev" : 0.001,
//probability of running this job with a reservation
"chance_of_reservation" : 0.5,
//input parameters of LogNormal distribution that determines the deadline slack (as a multiplier of job duration)
"deadline_factor_avg" : 10.0,
"deadline_factor_stddev" : 0.001,
}
],
// for each workload determines with what probability each time bucket is picked to choose the job starttime.
// In the example below the jobs have twice as much chance to start in the first minute than in the second minute
// of simulation, and then zero chance thereafter.
"time_distribution" : [
{ "time" : 1, "weight" : 66 },
{ "time" : 60, "weight" : 33 },
{ "time" : 120, "jobs" : 0 }
]
}
]
}
これは、1つのラックに編成された3つのノードを持つ入力トポロジファイルの例です。
{
"rack" : "default-rack",
"nodes" : [ {
"node" : "node1"
}, {
"node" : "node2"
}, {
"node" : "node3"
}]
}
対数正規分布は、実際に目にする多くのパラメーターをよく表しています(たとえば、ほとんどのジョブは少数のマッパーを持っていますが、非常に大きいものもあれば、非常に小さいものもありますが、ゼロより大きいです。ただし、平均は通常、分布のピーク(最も一般的な値)の右側にあるため、使用するのは難しい場合があります。これは、分布に片側テールがあるためです。